
In high-stakes responses, “almost right” can actually get deals delayed, escalated, or ‘gulp’ dropped. Yet ‘almost right’ is exactly what teams settle for when they rely on generic LLMs for RFPs, DDQs, security questionnaires, and responses to buyer questions. Is more speed worth risking accuracy, trust, or even the deal?
It’s a dangerous tradeoff, especially given how much the B2B buyer landscape has changed. Buyers are moving faster and forming opinions earlier than most revenue teams realize. 90% of B2B buyers research before engaging a vendor, and nearly two-thirds use generative AI as much as traditional search during discovery and evaluation. They may even forgo reading your website in favor of asking AI to summarize you, compare you, and tell them what to worry about.
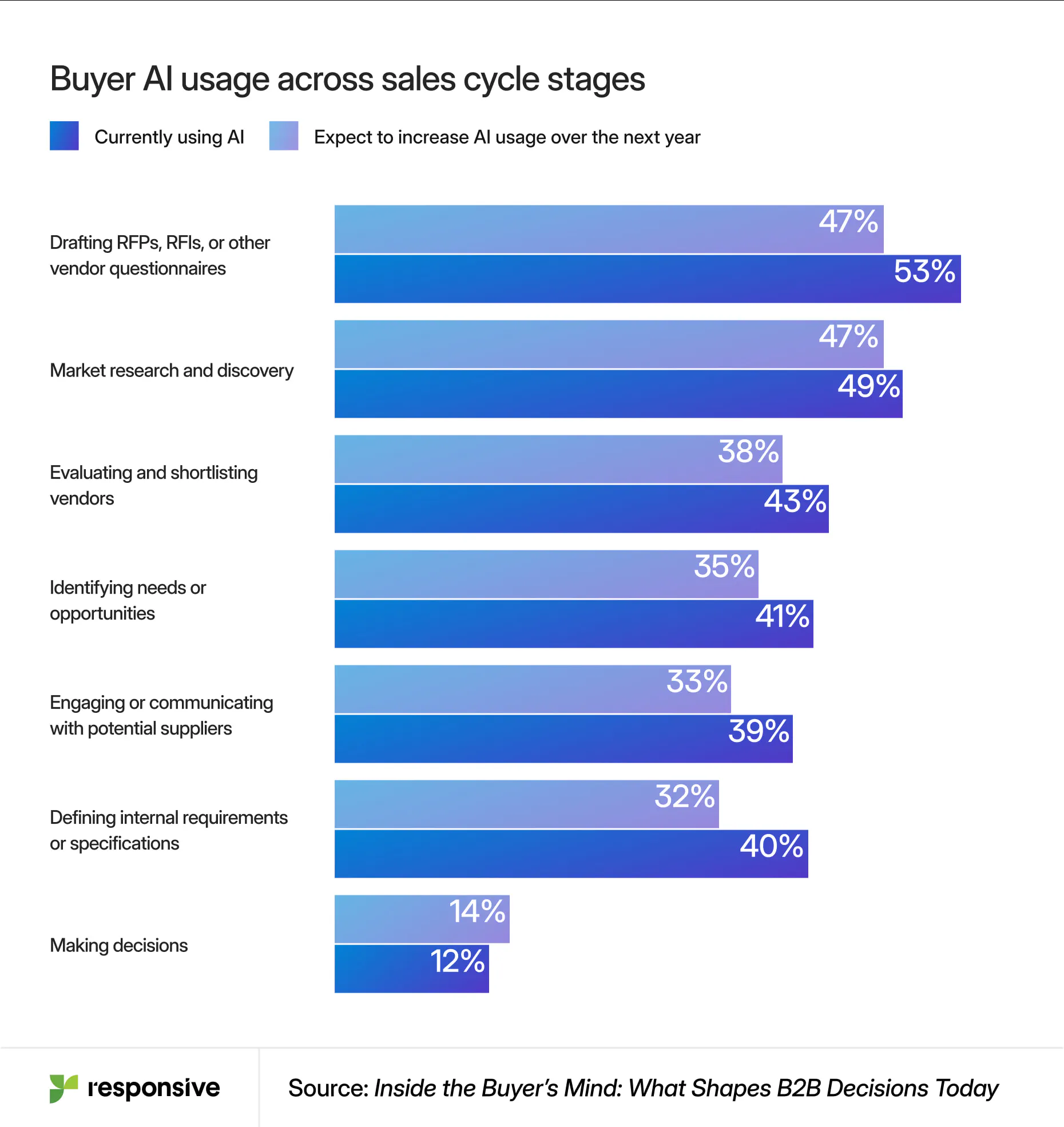
At the same time, the pressure inside the revenue engine is spiking. More than 75% of organizations say buyers have tighter budgets, expect faster response times, and require a higher degree of personalization.
To keep up, many teams turn to LLMs like ChatGPT, hoping they can handle the growing volume and speed of buyer requests. At first, it works, but it doesn’t take long for the cracks to show.
How to equip every team with trusted, winning answers
Where generic LLMs fall short in RFPs and questionnaires
LLMs are built for language. Accountability has to either be owned by human review or engineered into the AI. Generic LLMs like ChatGPT generate answers based on probability instead of your company’s approved knowledge, compliance standards, or positioning. That creates a gap between what’s fast and what’s defensible.
In high-stakes responses like RFPs, DDQs, and security questionnaires, that gap becomes visible:
- Answers sound polished, but lack specificity or differentiation
- Security responses vary depending on who’s prompting the tool
- Outdated or incorrect claims slip through
- Tone and positioning drift from your brand
- Teams spend more time reviewing AI output than writing
Without structure, ownership, and governance, AI has no reliable source of truth to work from.
The promise of generic AI, and the gap it creates
On the surface, LLMs look like the perfect solution. They can draft answers in seconds, summarize long documents, and help teams keep up with rising demand. For proposal teams buried under deadlines or sellers trying to respond in real time, that speed is hard to ignore.
But the real dependency behind any AI system isn’t the model: it’s the data. This is where many teams overestimate what LLMs can do. Even enterprise-grade models don’t inherently know which answers are approved, which data is current, or how to reconcile conflicting information across sources. They’re not designed to turn messy, fragmented knowledge into customer-ready truth.
There’s also a misconception that AI will reduce the need to manage content. In reality, it does the opposite. When knowledge is inconsistent or ungoverned, LLMs expose it but can’t fix it. They surface outdated claims, blend conflicting inputs, and generate answers that sound plausible but aren’t reliable enough to stand behind.
Generic LLMs don’t know your business. They don’t know what’s approved, what’s outdated, or what carries risk. They generate what sounds right, not what is right for your company, your buyer, or your deal.
That gap surfaces quickly in RFPs, DDQs, and security questionnaires. The answers may sound polished, but they lack specificity, and details shift depending on different users’ prompts. Before long, small inconsistencies add up, and what felt like acceleration starts to feel like rework.
LLM hallucinations expose the knowledge problem
Most organizations already have the answers they need. They live in past proposals, in security responses that passed audits, and in the language that helped win deals. This knowledge is proven, specific, and valuable.
But it’s not usable if it’s scattered across documents, buried in folders, and locked in the minds of subject matter experts (SMEs). Teams don’t trust what they find, so they recreate it or bypass it entirely. Then, when ChatGPT or another LLM enters the picture, it amplifies fragmentation and begins building wrong answers based on wrong answers.
When LLMs are layered onto fragmented knowledge, the risks compound rapidly:
- Responses become generic or inconsistent
- Security answers vary and trigger scrutiny
- Sellers rely on answers they can’t fully validate
- Messaging drifts across teams and touchpoints
These small cracks show up at the worst possible moment: when buyers are narrowing options and validating risk. And once a buyer notices inconsistency, trust erodes quickly.
The SRM difference: from generating answers to trusting them
Instead of asking, “How do we generate answers faster?” leading organizations ask: “How do we ensure every answer is accurate, consistent, and defensible before AI touches it?”
That shift leads to a different operating model built on Strategic Response Management (SRM): centralizing, governing, and activating knowledge so every response holds up under scrutiny.
In practice, it comes down to four moves.
1. Create a single source of truth (and make it usable)
Your best answers already exist, but they need to be structured for reuse.
High-performing teams break knowledge into clean, reusable Q&A pairs that are properly tagged and organized around how the business actually responds to buyers. This is what makes knowledge usable by AI. Without structure, even the best content becomes unreliable at scale.
2. Add governance so answers can be trusted
LLMs struggle most when the data behind them is inconsistent or out of date. Governance solves that problem at the source, bringing structure and clarity before AI is ever applied. Each answer is owned, reviewed, and clearly labeled, with changes tracked and freshness visible, so teams can move quickly, knowing exactly what they can trust.
Responsive embeds this directly into the system:
- A centralized Content Library with role-based access and content-level controls
- Structured review workflows and moderation to verify content before use
- Built-in reporting to track content health, usage, and review status
AI then reinforces governance instead of bypassing it. Responsive AI agents flag outdated or duplicate content, routes items for review, and helps maintain quality over time.
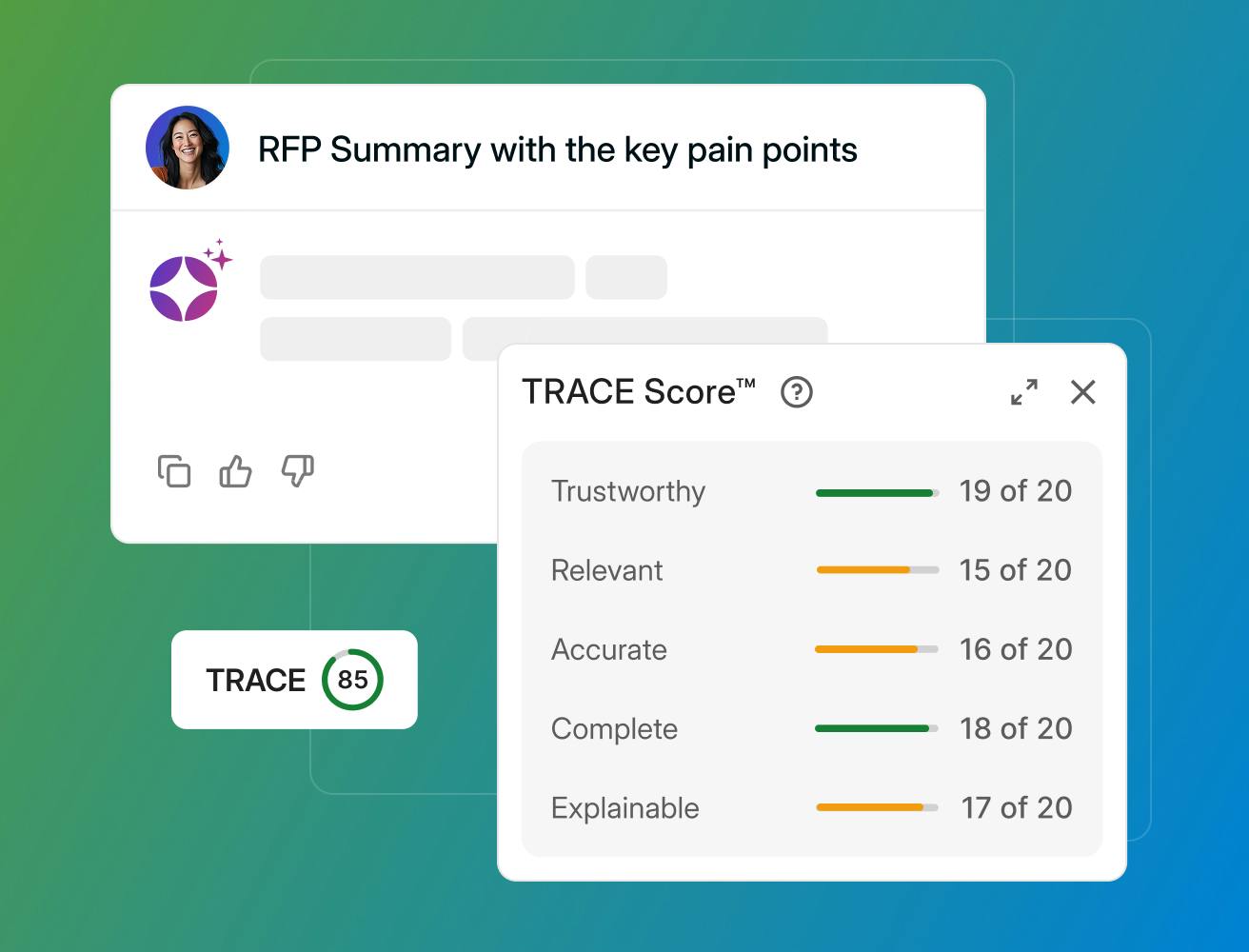
Most importantly, AI outputs are grounded in approved content instead of the open web. Using a retrieval-augmented generation (RAG) approach, responses include source citations and can be validated before use. TRACE Score™ adds a final layer of confidence, evaluating each answer for accuracy, relevance, and completeness.
This is the difference between AI that generates unreliable answers and AI you can trust.
3. Enable self-service without introducing risk
Once knowledge is trusted, access can scale with conversational AI like Responsive Ask.
Instead of routing every question through proposal or SME teams, organizations enable self-service so sellers, solutions engineers, and security teams can retrieve answers instantly, in their workflow.
What makes this work is control. When guardrails like permissions, content restrictions, and validated sources are built into the system, teams can move quickly without creating variability. Over time, shadow documents disappear, repetitive questions fade, and proposal teams spend less time coordinating and more time shaping the response. Speed follows naturally, because trust is already in place.
4. Continuously improve the system
Leading teams treat their knowledge base as a living system. They monitor content health, track usage, and identify gaps based on real buyer questions.
AI plays a role here, too. It not only generates answers, it also curates the source knowledge database by:
- Flagging stale or conflicting content
- Identifying duplicates
- Routing updates to the right owners
Over time, the system improves itself with stronger answers, building trust and advancing adoption.
When AI is connected to governed knowledge, its role shifts
When AI stops guessing and starts delivering, proposal teams begin with strong drafts instead of blank pages. Sales responds faster with answers they trust. Security and compliance operate from consistent, audit-ready content. Marketing maintains control of the narrative.
The entire revenue engine moves faster when AI is built on truth.
Generic LLMs are dangerous because they’re generic. And generic responses for RFPs, DDQs, and high-stakes buyer interactions have a better chance of introducing more risk than closing a deal. With AI powered by SRM, teams can answer quickly and stand behind that answer with confidence.
Want to dive deeper? Check out The Guide to Turning Organizational Knowledge into Revenue.

RD Symms
Sr. Copywriter @ Responsive
With more than 15 years in writing, content development, and creative strategy, RD brings a rare combination of conceptual thinking and executional range to the proposal management space. He's spent his career turning complex ideas into content that earns attention which makes him a natural fit for an audience of proposal managers and sales leaders who read critically and buy carefully.